1. 기본 개요
ㅁ. 스파크 머신 러닝 (스파크 MLlib 모듈)
스파크 MLlib 모듈은 여러 도메일을 아우를 수 있는 머신 러닝(Machine Learning) 기능을 제공한다. 스파크 웹 사이트에서 제공하는 문서를 보면 MLlib 모듈이 처리 가능한 데이터 타입(벡터와 LabelPoint 구조)를 소개한다.
스파크 MLlib 모듈은 다음과 같은 기능을 제공한다.
- 통계(Statistics)
- 분류(Classification)
- 회귀(Regression)
- 협업 필터링(Collaborative Filtering)
- 클러스터링(Clustering)
- 차원 축소(Dimessionality Reduction)
- 특징 추출(Feature Extraction)
- 빈발 패턴 마이닝(Frequent Pattern Mining)
- 최적화(Optimization)
ㅁ 스파크 Streaming
스트림 프로세싱(Stream Processing)은 스파크 데이터를 스트리밍 형태로 처리하는 데, 주요 토픽으로는 입출력 명령, 변환(transformations), 유지(Persistence), 검사점(Check Pointing)등이 있다.
스트림 데이터를 처리하는 방법은 SQL, MLlib, GraphX등과 같은 다른 스파크 서브 모듈에서도 스트림을 처리하는 기능을 제공하고 있을 뿐만 아니라, Kinesis, ZeroMQ 등과 같은 시스템을 이용하여 스파크 스트리밍을 다루 수도 있다. 심지어는 자신만의 리시버를 만들어 자신이 디자인한 데이터를 처리할 수 있다.
ㅁ. 스파크 SQL
스파크 버전 1.3 부터 데이터 프레임이 아파치 스파크에 소개되어 스파크 데이터가 테이블 형태로 처리되거나 데이터를 처리하기 위해 Select, filter, groupBy 등과 같은 테이블 함수를 사용할 수 있게 되었다.
또한 스파크 SQL 모듈이 Parquet과 JSON 포맷과 통합하여 각각의 포맷으로 데이터를 저장하고 표현할 수 있게 됨으로써, 또 다른 확장 시스템과 통합할 수 있는 다양한 옵션을 제공할 수 있게 되었다.
아파치 스파크를 빅데이터 데이터베이스인 하둡 하이브에 통합할 수도 있다. 하이브 문법 기반으로 구성된 스파크 애플리케이션은 하이브 기반의 테이블 데이터를 다루는데 사용될 수 있으며, 이를 통해 스파크의 빠른 인메모리 분산 처리 방식을 하이브의 빅데이터 스토리지로 확장할 수 있게 되었다.
ㅁ. 스파크 그래프 프로세싱
아파치 스파크 GraphX 모듈은 빅데이터를 위한 빠른 인메모리(In-Memory) 그래프 프로세싱을 제공한다. 그래프는 정점(Vertex 또는 Node)와 간선(edge)의 조합을 일컫는다. GraphX는 Property, structural, join, aggregation, cache, unchace 연산 등을 사용하여 그래프를 생성하고 처리한다.
스파크는 그래프 프로세싱을 지원하기 위해 정점과 간선을 의미하는 VertexRDD와 EdgeRDD라는 두 가지 새로운 데이터 타입을 제시하고 이를 이용해서 PageRank, 삼각형 카운팅과 같은 그래프를 계산하는 함수도 선보였다.
2. 클러스터 관리
아래의 그림은 spark.apache.org 웹 사이트에 게시된 것으로, 마스터, 슬레이브(worker), executor, 스파크 클라이언트 애플리케이션 관점에서의 아파치 스파크 클러스터 매니저의 역할을 보여준다.
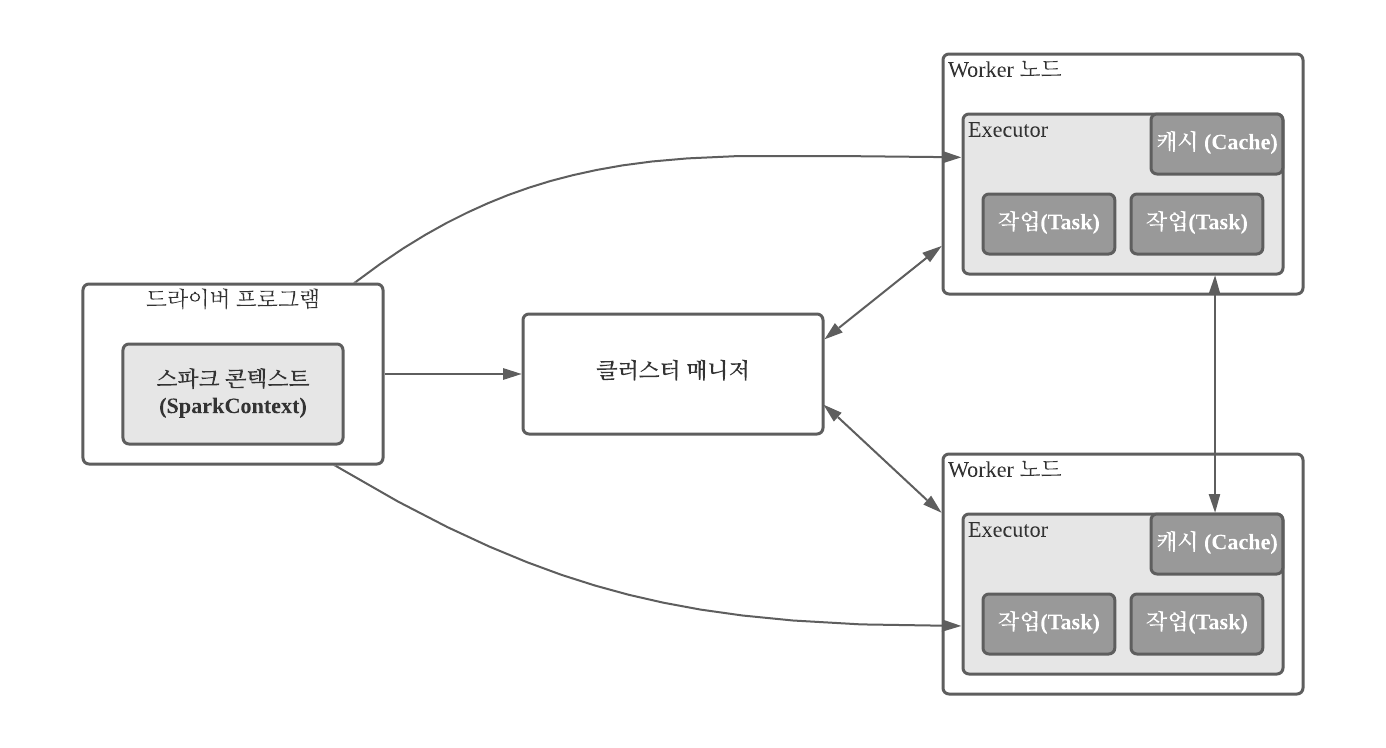
- 스파크 콘텍스트(Context)는 스파크 설정 객체 및 스파크 URL을 통해 정의 될 수 있다.
- 스파크 컨텍스트가 스파크 클러스터 매니저로 넘어가면 스파크 클러스터 매니저가 애플리케이션에 필요한 Worker 노드에 자원 및 executor를 할당 시킨다. 그리고 애플리케이션의 jar파일을 worker 노드에 복사한 후 마지막으로 작업을 할당 시킨다.
3. 스파크 기본 특징
스파크는 인메모리 분산 프로세싱을 통한 빠른 속도 때문에 사용됨에도 불구하고 스토리지를 제공하지 않는다. 물론 호스트의 파일 시스테믈 을 이용하여 데이터 읽기 쓰기를 할 수 있지만 빅데이터와 같이 데이터의 규모가 엄청난 경우 하둡과 같은 분산 스토리지 시스템을 사용한다.
아울러 아파치 스파크는 오직 ETL(Extract, Transform, Load -추출, 변환, 적재) 과정의 프로세싱 단계에서만 사용된다. 즉, 아파치 스파크는 하둡 생태게에서 사용되는 툴 세트를 제공하지 않으므로 데이터 수집을 위해 Nutch, Gora, Solr를 데이터 이동을 위해 Sqoop와 Flume을 스케줄링을 위해 Oozie를, 스토리지를 위해 HBase나 Hive가 필요하다.