MariaDB Solution Set

MariaDB TX는 읽기만 확장이 가능했는데 쓰기도 확장이 가능한 솔루션으로 Xpand로 대안 제품이 출시
별도의 Master Node가 없이 구성됨, 어떤 노드

Xpand는 Scale Out 형태로 20대 ~ 30대의 형태로 만들 수 있다. 중간에 Load Balancer가 어떤 타입으로도 들어올 수 있다. Application Serve에서도 로직을 구현해 가능 but LB를 구성하는 것을 제안
기본적으로는 Round Robin 방식이나 각 LB의 특성에 따라 구현 가능

AWS의 EC2로 구성 시 Xpand가 구성된 AMI를 기존 Xpand Cluster에 바로 연결하여 확장 가능하다.
확장이 되면서 기존 Node에 저장되어 있는 기존 데이터의 신규 Node로의 이동은 옵션에 따라 시간이 달라진다.

Hadoop은 3 Copy, Xpand는 2 Copy의 중복된 데이터를 각 노드에 저장됨, 옵션을 3 copy로 변경 가능
Max Failure라는 개념으로 한번에 동시에 떨어지는 것을 감내할 수 있는것을 MaxFailure=1, 2개가 동시에 떨어지는 것을 감내할 수 있는 것을 MaxFailure=2로 설정 가능

Xpand는 NoSQL이 아님, RDBMS임
만약 Node가 1대 떨어졌다 다시 붙는데까지의 임계치는 10분 기준(Default Option, 변경 가능), 즉 10대의 Cluster Node에서 1대의 장애 발생 시 10분내 다시 붙으면 기존 정보로 운영, 10분이 넘어가면 Eject 진행, 10분이후 다시 해당 Node가 다시 붙으면 신규 Node로 인식됨

AWS, Azure와 같은 Cloud 환경에서 잘 작동함, 각 노드간 Network 대역폭을 어떻게 관리하느냐에 따라 성능 요소가 달라짐.
최소 10G 이상이며 데이터 전달 대역폭에 따라 달라질 수 있음


Hadoop은 Name Node가 있으나 Xpand는 Name Node가 없음. 10대의 Node 중 어떤 Node가 제거되도 운영에 문제 없음
Metadata도 각 Node에서 공유하고 있음.
Load Balancer는 MaxScale을 권장
10대나 20대를 운영하면서 EC2 1대 ~ 2대의 Instance가 자꾸 떨어지면서 문제가 있다고 생각이 되면
쿼럼에서 Group Change Operation이 일어남. 이 순간 일시적은 순단이 발생 (수초), 한번에 한대를 붙일때마다 발생,
3대 + 3대를 붙일 경우 한번의 Group Chagne 발생, but 3대 + 1 + 1+ 1 인 경우 3번의 Group Change 발생


Replica 2 기준으로 위에서 Used 데이터는 1.6T를 사용, Default로 데이터는 2Copy, 실제 데이터는 800G 사용중임
10대 노드로 확장 시 160


33,616 TPS --> 400,000 QPS (TPS 기준 12배 ~14배 정도)


동일 데이터 하나에 대해서 2군데 노드에 갖을 수 있게 슬라이싱
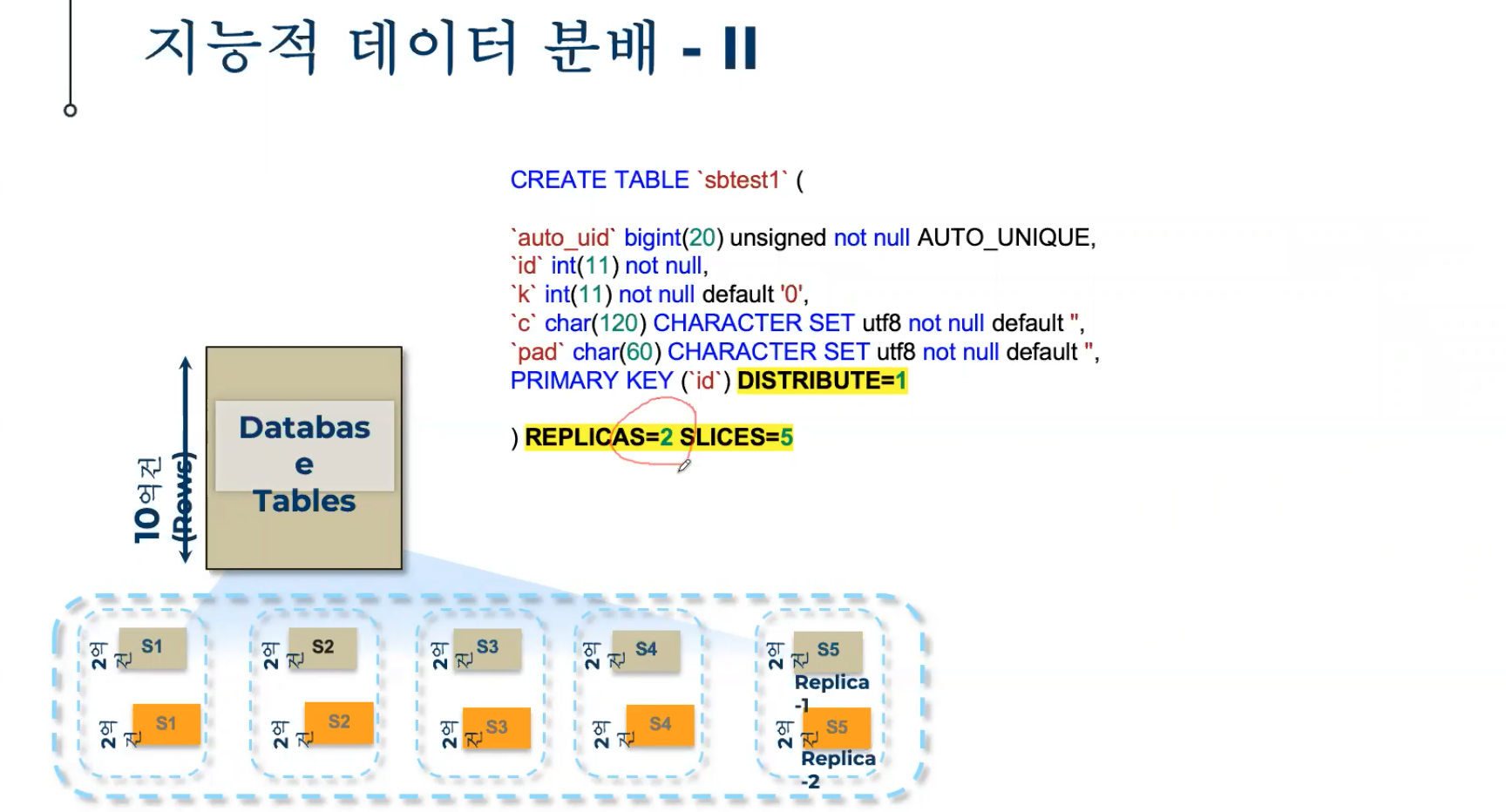
Replicas=2, Slices=5
복제는 2개로, 각 영역은 5개로 분산해서 구성한다.

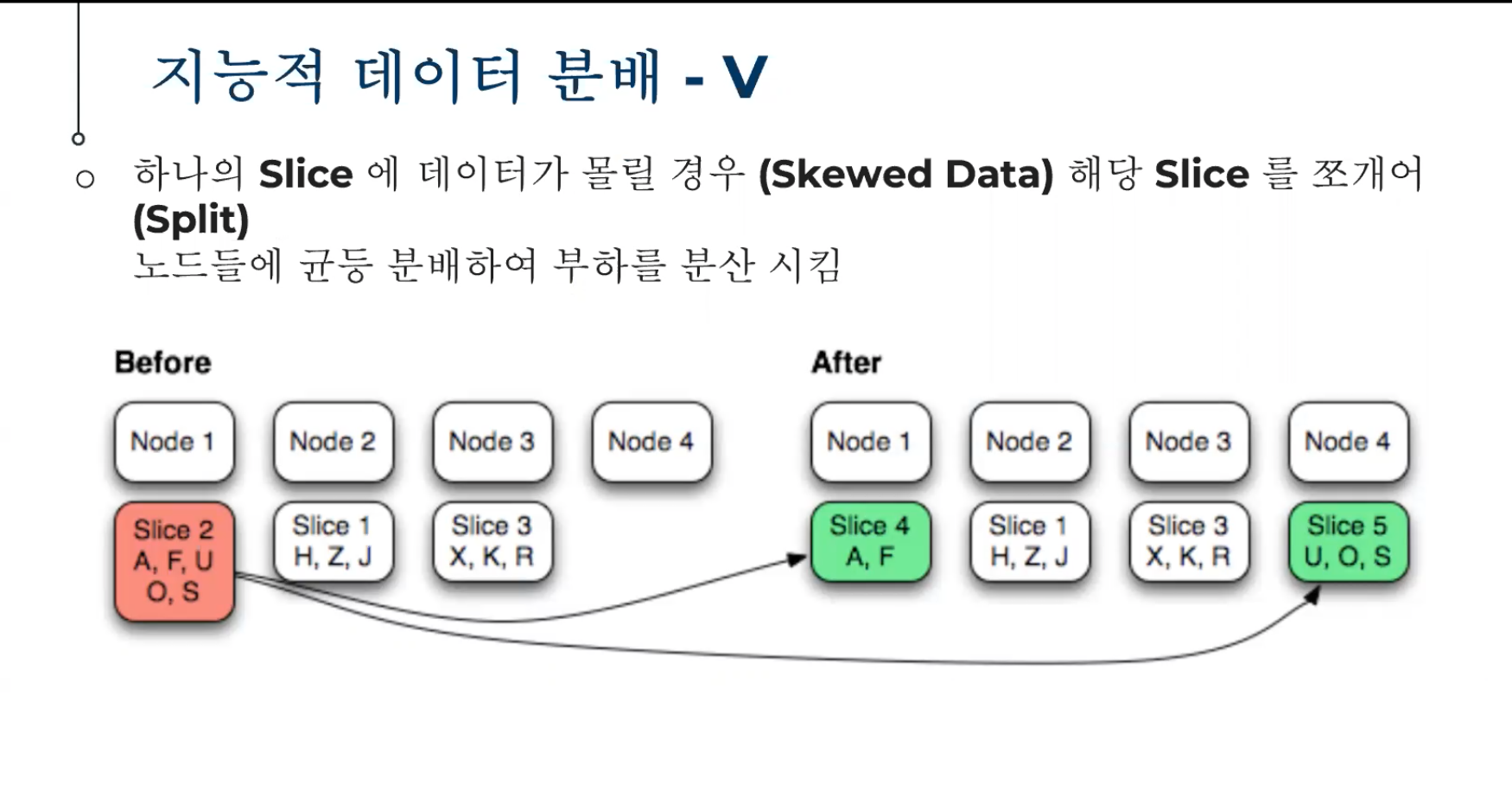
Node 1의 Slice 2가 임계치에 도달하면 쪼개서 다른 노드로 분배 시킴
Slice 2 A, F, U, O, S --> Slice 4 A,F / Slice 5 U, O, S 로 자동 분배
절대 데이터량이 증가하면 슬라이스수도 알아서 증가 (자동으로 쪼개서 나누어 버림)




Reprotect: Node가 떨어진 경우 바로 Rebalance 진행 (Node Fail시 추가로 Fault 발생하면 데이터 loss임으로)
Softfail: 의도적으로 Node를 삭제 했을 경우
Reap: Node 추가
Split: 데이터가 폭증 할 경우
Rerank: 2 Copy 유지 시 Read 할 경우 한 쪽에서만 읽으면 되기 때문에 Replica 1, 2번 중에 읽기 시에는 2번만 사용해
2번을 열심히 읽고 있는데 2번의 부하가 걸리 경우 다른 1번쪽으로 Read가 가도록 Rerank 작업을 함.
Rebalance: Node나 Disk Usage에 따라서 Rebalance 작업 진행 (부하가 없을 때 진행)

쓰기 부하를 끌어올릴 때 3 Copy 나 2 Copy 동시 Write 시에 부하가 크게 올라가지는 않음

AWS의 각 AZ 영역을 고려해서 구성
하나의 데이터는 가능한 2개 이상의 Zone에 보유할 수 있도록 구성


Oracle RAC 운영 시 선형 확장이 아니기 때문에 Overhead 가 매우 큼
따라서 RAC 구성 시 각 Node별로 업무를 분산하여 사용
Xpand 는 RAC 보다 TPS를 끌어 올리기에 성능이 충분한
Xpand 는 Linear Scalability 10대에서 100% 20대는 180% 30대는 270% 정도 확장됨
Pain Point: Procedure는 Oracle 만큼 잘 처리하지는 못함
Oracle --> Xpand로 옮기는 것은 완전히 다른 DB를 사용하는 것임
그 애플리케이션에 대한 변경작업은 반드시 필요함
대규모 시스템인 경우 처음부터 Xpand로 가는 것을 추천, 오라클 to Xpand는 Migration 프로젝트 비용을 감수해야 함

Xpand 는 Open Source가 아님

이때 Read/Write에서 Write 성능을 높이기 위해서 Xpand로 변경 (과도한 쓰기로 인한 부하 발생)
각 리전별로 수십대씩 구성하여 사용 진행 중
