AWS S3 Overview - Buckets
- Amazon S3 allows people to store objects (files) in "buckets" (directories) (Amazon S3를 사용하면 "buckets" (directories)에 object(file)을 저장할 수 있음.)
- Buckets must have a globally unique name (bucket은 전역적으로 고유한 이름이어야 함)
- Buckets are defined at the region level (bucket은 region level에서 정의된다)
- Naming convention (명명 규칙)
* No uppercase (대문자 사용 금지)
* No underscore (밑줄 없음)
* 3-63 characters long (3-63 자 길이)
* Not an IP (IP가 아님)
* Must start with lowercase letter or number
AWS S3 Overview - Objects
- Objects (files) have a Key. The key is the FULL path:
* <my_bucket>/my_file.txt
* <my_bucket>/my_folder1/another_folder/my_file.txt
- There's no concept of "directories" within buckets (although the UI will trick you to think otherwise)
- Just keys with very long names that contain slashes ("/")
- Object Values are the content of the body:
* Max Size is 5TB
* If uploading more than 5GB, must use "multi-part upload"
- Metadata (list of text key / value pairs - system or user metadata)
- Tags (Unicode key / value pair - up to 10) - useful for security / lifecycle
- Version ID (if versioning is enabled)
Amazon S3 - Consistency Model
- Strong consistency as of Dec 2020:
- After a:
* successful write of a new object (new PUT)
* or an overwrite or delete of an existing object (overwirte PUT or DELETE)
- ...any:
* subsequent read request immediately receives the lastes version of the object (read after write consistency)
* subsequent list request immediately reflects changes (list consistency)
- Available at no additional cost, without any performance impact
S3 Storage Classes
- Amazon S3 Standard - General Purpose
- Amazon S3 Standare-Infrequent Access (IA)
- Amazon S3 One Zone-Infrequent Access
- Amazon S3 Intelligent Tiering
- Amazon Glacier
- Amazon Glacier Deep Archive
- Amazon S3 Reduced Redundancy Storage (deprecated-omitted)
S3 Standard - General Purpose
- High durability (99.999999999%) of objects across multiple AZ
- If you store 10,000,000 objects with Amazon S3, you can on average e xpect to incur a loss of a single object once every 10,000 years
- 99.99% Availability over a given year
- Sustain 2 concurrent facility failures
- Use Cases: Big Data analytics, mobile & gaming applications, content distribution...
S3 Standard - Infrequent Access (IA)
- Suitable for data that is less frequently accessed, but requires rapid access when needed
- High durability (99.999999999%) of objects across multiple AZs
- 99.9% Availability
- Low cost compared to Amazon S3 Standard
- Sustain 2 concurrent facility failures
- Use Cases: As a data store for disaster recovery, backups...
S3 One Zone - Infrequent Access (IA)
- Same as IA but data is stored in a single AZ
- High durability (99.999999999%) of objects in a single AZ; data lost when AZ is destroyed
- 99.5% Availability
- Low latency and high throughput performance
- Supports SSL for data at transit and encryption at rest
- Low cost compared to IA (by 20%)
- Use Cases: Storing secondary backup copies of on-premise data, or storing data you can recreate
S3 Intelligent Tiering
- Same low latency and high throughput performance of S3 Standard
- Small monthly monitoring and auto-tiering fee
- Automatically moves object between two access tiers based on changing access patterns
- Designed for durability of 99.999999999% of objects across multiple Availability Zones
- Resilient against events that impact an entire Availability Zone
- Designed for 99.9% availability over a given year
Amazon Glacier
- Low cost object storage meant for archiving / backup
- Data is retained for the longer term (10s of years)
- Alternative to on-premise magnetic tape storage
- Average annual durability is 99.999999999%
- Cost per storage per month ($0.004/GB) + retrieval cost
- Each item in Glacier is called "Archive" (up to 40TB)
- Archives are stored in "Vaults"
Amazon Glacier & Glacier Deep Archive
- Amazon Glacier - 3 retrieval options:
* Expedited (1 to 5 minutes)
* Standard (3 to 5 hours)
* Bulk (5 to 12 hours)
* Minimum storage duration of 90 days
- Amazon Glacier Deep Archive - for long term storage - cheaper:
* Standard (12 hours)
* Bulk (48 hours)
* Minimum storage duration of 180 days
S3 Storage Classes Comparison
| S3 Standard | S3 Intelligent- Tiering |
S3 Standard-IA | S3 One Zone-IA |
S3 Glacier | S3 Glacier Deep Archive |
|
| Designed for durability | 99.999999999% (11 9's) | 99.999999999% (11 9's) | 99.999999999% (11 9's) | 99.999999999% (11 9's) | 99.999999999% (11 9's) | 99.999999999% (11 9's) |
| Designed for availability | 99.99% | 99.9% | 99.9% | 99.5% | 99.9% | 99.9% |
| Availability SLA |
99.9% | 99% | 99% | 99% | 99.9% | 99.9% |
| Availability zone |
>= 3 | >= 3 | >=3 | 1 | >=3 | >=3 |
| Minimum capacity charge per object |
N/A | N/A | 128KB | 128KB | 40KB | 40KB |
| Minimum storage duration charge |
N/A | 30 days | 30 days | 30 days | 90 days | 180 days |
| Retreval fee | N/A | N/A | per GB retrieved | per GB retrieved | per GB retrieved | per GB retrieved |
S3 Storage Classes - Price Comaprison Example us-east
| S3 Standard | S3 Intelligent- Tiering |
S3 Standard-IA | S3 One Zone-IA |
S3 Glacier | S3 Glacier Deep Archive |
|
| Storage cost (per GB per month) |
$0.023 | $0.0125-$0.023 | $0.0125 | $0.01 | $0.004 Minimu 90days |
$0.00099 Minimum 180 days |
| Retrieval Cost (per 1000 request | GET $0.0004 | GET $0.0004 | GET $0.001 | GET $0.001 | GET $0.0004 + Expedited - $10.00 Standard - $0.05 Bulk - $0.025 |
GET $0.0004 + Standard - $0.10 bulk - $0.025 |
| Time to retrieve | Instantaneous | Instantaneous | Instantaneous | Instantaneous | Expedited (1 to 5 minutes) Standard (3 to 5 hours) Bulk (5 to 12 hours) |
Standard (12 hours) Bulk (48 hours) |
S3 - Moving between storage classes

- 스토리지 클래스 간에 개체를 전환 가능
- 접근 빈도가 낮은 객체는 STANDARD_IA로 이동
- 실시간으로 필요하지 않는 아카이브 객체의 경우 GLACIER 또는 DEEP_ARCHIVE
- Moving objects can be automated using a lifecycle configuration
S3 Lifecycle Rules
- Transition actions: Object가 다른 스토리지 클래스로 전환되는 시기를 정의
* Object를 생성한 후 60일 후 Standard IA 클래스로 이동
* 6개월 후 보관을 위해 Glacier로 이동
- Expiration actions: 일정 시간 후 만료(삭제) 되도록 객체 구성
* Access log files은 365일 후에 삭제 되도록 설정 가능
* 파일의 이전 버전을 삭제하는데 사용 가능(Versioning Enable시)
* 불완전한 multi-part 업로드를 삭제하는 데 사용 가능
- 특정 접두사에 대한 Rule 생성 가능 (ex-s3://mybucket/mp3/*)
- 특정 Object Tag에 대한 Rule 생성 가능 (ex-Department: Fianance)
S3 Lifecycle Rules - Scenario 1
- Your application on EC2 creates images thumbnails after profile photos are uploaded to Amazon S3. These thumbnails can be easily recreated, and only need to be kept for 45 days. The source images should be able to be immediately retrieved for these 45 days, and afterwards, the user can wait up to 6 hours. How would you design this?
( EC2의 애플리케이션은 프로필 사진이 Amazon S3에 업로드된 후 이미지 축소판을 생성합니다. 이 썸네일은 쉽게 다시 만들 수 있으며 45일 동안만 보관하면 됩니다. 소스 이미지는 이 45일 동안 즉시 검색할 수 있어야 하며 그 이후에는 사용자가 최대 6시간을 기다릴 수 있습니다. 이것을 어떻게 디자인하시겠습니까?)
- S3 source images can be on STANDARD, with a lifecycle configuration to transition them to GLACIER after 45 days.
- S3 thumbnails can be on ONEZONE_IA, with a lifecycle configuration to expire them (delete them) after 45 days.
S3 Lifecycle Ruels - Scenario 2
- A rule in your company states that you should be able to recover your deleted S3 objects immediately for 15 days, although this may happend rarely. After this time, and for up to 365 days, deleted objects should be recoverable within 48 hours.
(회사의 규칙에 따르면 삭제된 S3 객체를 15일 동안 즉시 복구할 수 있어야 하지만 드물게 발생할 수 있습니다. 이 시간이 지나면 최대 365일 동안 삭제된 개체를 48시간 이내에 복구할 수 있습니다.)
- You need to enable S3 versioning in order to have object versions, so that "deleted objects" are in fact hidden by a "delete marker" and can be recovered
- You can transition these "noncurrent versions" of the object to S3_IA
- You can transition afterwards these "noncurrent versions" to DEEP_ARCHIVE
Amazon S3 - Versioning
- You can version your files in Amazon S3
- It is enabled at the bucket level
- Same key overwrite will increment the "version": 1, 2, 3...
- 동일한 키 덮어쓰기는 "version"을 증가시킴. 1, 2, 3 ...
- It is best practice to version your buckets
* 의되하지 않은 삭제로부터 보호 (버전 복원 기능)
* 이전 버전으로 쉽게 롤백
- Notes:
* 버전 관리를 활성화하기 전에 버전이 지정되지 않은 모든 파일의 버전은 "null"
* 버전 관리를 일시 중단해도 이전 버전은 삭제되지 않음
S3 Replication (CRR & SRR)
- source 및 destination에서 versioning을 활성화 해야 함.

- Cross Region Replication (CRR)
- Same Region Replication (SRR)
- Buckets은 다른 계정에 있을 수 있다.
- Copying is asynchronous
- S3에 적절한 IAM 권한을 부여
- CRR - Use cases: compliance, lower latency access, replication across accounts
- SRR - Use cases: log aggregation, live replication between production and test accounts
S3 Replication - Notes
- After activating, only new objects are replicated (not retoractive)
- For DELETE operations:
* Can replicate delete markers from source to target (optional setting)
* Deletions with a version ID are not replicated (to avoid malicious deletes)
- There is no "chaining" of replication (복제에는 연쇄가 없음)
* 만약 bucket 1에 bucket 2에 대한 복제가 있고 bucket 3에 복제가 있는 경우
* bucket 1에서 생성된 object가 bucket 3로 복제 되지 않음.
S3 - Baseline Performance
- Amazon S3 automatically scales to high request rates, latency 100-200ms
- Your application can achieve at least 3,500 PUT/COPY/POST/DELETE and 5,500 GET/HEAD requests per second per prefix in a bucket.
- There are no limits to the number of prefixes in a bucket.
- Example (object path => prefix):
* bucket/folder1sub1/file => /folder1/sub1/
* bucket/folder1/sub2/file => /folder1/sub2/
* bucket/1/file => /1/
* bucket/2/file => /2/
- 4개의 모든 접두사에 균등하게 읽기를 분산하면 GET 및 HEAD에 대해 초당 22,000개의 Request를 달성 가능
S3 - KMS Limitation

- If you use SSE-KMS, you may be impacted by the KMS limits
- When you upload, it calls the GenerateDataKey KMS API
- When you download, it calls the Decrypt KMS API
- Count towards the KMS quota per second (5500, 10000, 30000 req/s based on region)
- You can request a quota increase using the Service Quotas Console
S3 Performance
- Multi-Part upload:
* 100MB이상의 파일에 권장, 5GB이상의 파일에 사용해야 함
* 업로드 병렬화를 도울 수 있다. (전송 속도 향상)

- S3 Transfer Acceleration
* Increase transfer speed by trnasferring file to an AWS edgelocation which will forward the data to the S3 bucket in the target region
* multi-part 업로드와 호환

S3 Performance - S3 Byte-Range Fetches
- 특정 byte 범위를 요청하여 Get 병렬화
- 실패시 복원력 향상
Can be used to speed up downloads

Can be used to retrieve only partial data (for example the head of a file)

S3 Encryption for Objects
- There are 4 methods of encrypting objects in S3
* SSE-S3: AWS에서 처리 및 관리하는 키를 사용하여 S3 Object 암호화
* SSE-KMS: AWS Key Management Service를 활용하여 암호화 키 관리
* SSE-C: 자신의 암호화 키를 관리하고 싶을 때
* Client Side Encryption
- It's important to understand which ones are adapted to which situation for the exam
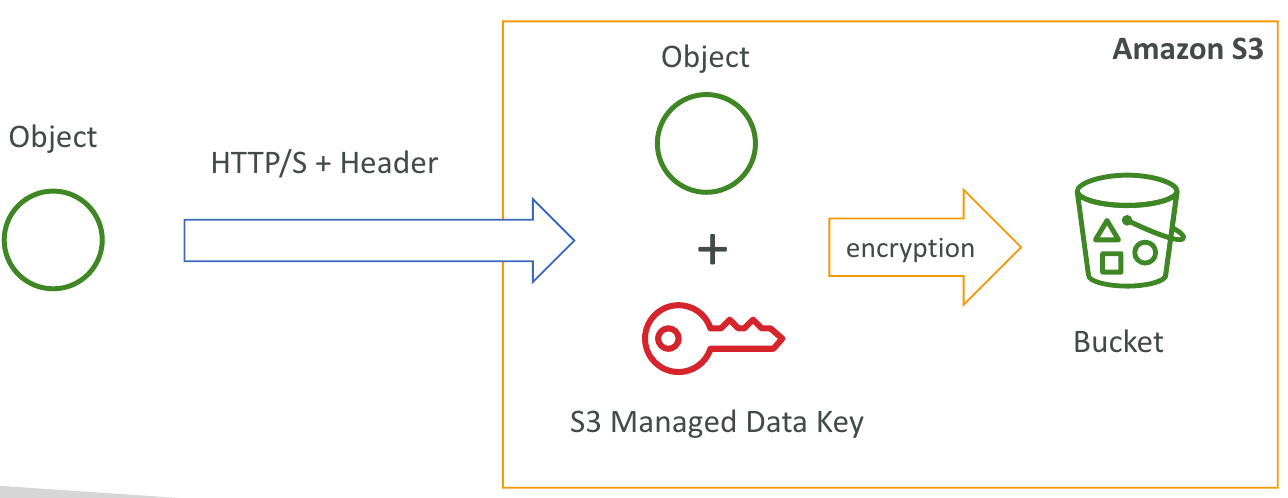
SSE-S3
- SSE-S3: Amazon S3에서 처리 및 관리하는 키를 사용한 암호화
- Object i encrypted server side
- AES-256 encryption type
- header를 설정해야 함: "x-amz-server-side-encryption": "AES256"
SSE-KMS
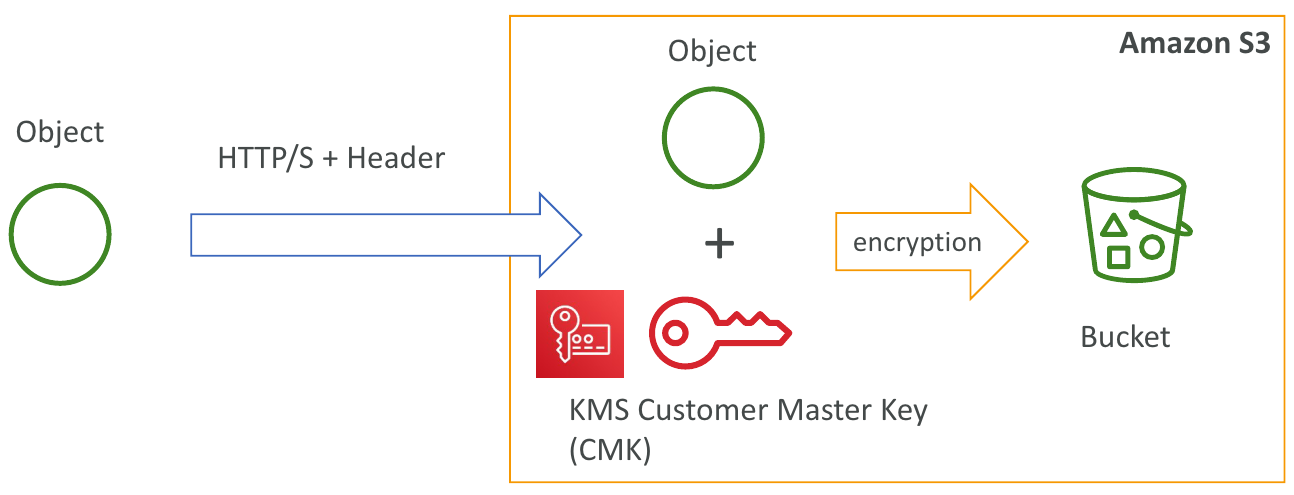
- SSE-KMS: KMS에서 처리 및 관리하는 키를 사용한 암호화
- KMS Advantages: 사용자 제어 + 감사 추적
- Object가 암호화된 서버 측
- 헤더를 설정해야 함: "x-amz-server-side-encryption": "aws:kms"
SSE-C
- SSE-C: AWS 외 부에서 고객이 완전히 관리하는 데이터 키를 사용한 서버측 암호화
- Amazon S3는 사용자가 제공한 암호화 키를 저장하지 않음
- HTTPs를 사용해야 함
- 모든 HTTP 요청이 객체를 생성할 때마다 HTTP 헤더에 암호화 키를 제공해야 함.

Client Side Encryption
- Client library such as the Amazon S3 Encryption Client
- Clients must encrypt data themselves before sending to S3
- Clients must decrypt data themselves when retrieving from S3
- Customer fully manages the keys and encryption cycle

Encryption in transit (SSL/TLS)
- Amazon S3 exposes:
* HTTP endpoint: non encrypted
* HTTPS endpoint: encryption in flight
- You're free to use the endpoint you want, but HTTPS is recommended
- Most client would use the HTTPS endpoint by default
- HTTPS is mandatory for SSE-C
- Encryption in flight is also called SSL/TLS
S3 Security
- User based
* IAM 정책 - IAM 콘솔에서 특정 사용자에 대해 허용되어야 하는 API 호출
- Resource Based
* Bucket 정책 - S3 콘솔의 Bucket 전체 규칙 - 교차 계정 허용
* Object 액세스 제어 목록 (ACL) - 더 세분화된 제어
* Bucket 액세스 제어 목록 (ACL) - 덜 일반적임
- Note: an IAM principal can access an S3 object if
* the user IAM permissions allow it OR the resource policy ALLOWS it
* AND there's no explicit DENY
S3 Bucket Policies

- JSON based policies
* Resources: buckets and objects
* Actions: Set of API to Allow or Deny
* Effect: Allow / Deny
* Principal: The account or user to apply the policy to
- Use S3 bucket for policy to:
* Grant public access to the bucket
* Force objects to be encrypted at upload
* Grant access to another account (Cross Account)
Bucket settings for Block Public Access
- Block public access to buckets and objects granted through
* new access control lists (ACLs)
* any access control lists (ACLs)
* new public bucket or access point policies
- Block public and cross-account access to buckets and objects throught any public bucket or access point policies
- These settings were created to prevent company data leaks
- If you know your bucket should never be public, leave these on
- Can be set at the account level
S3 Security - Other
- Networking:
* Supports VPC Endpoints (for instances in VPC without www internet)
- Logging and Audit:
* S3 Access Logs can be stored in other S3 bucket
* API calls can be logged in AWS CloudTrail
- User Security:
* MFA Delete: MFA (Multi Factor Authentciation) can be required in versioned buckets to delete objects
* Pre-Signed URLs: URLs that are valid only for a limited time (ex: premium video service for logged in users)
S3 Select & Glacier Select
- Retrieve less data using SQL by performing server-side filtering
- Can filter by rows & columns (simple SQL statements)
- Less network transfer, less CPU cost client-side
- Note: Glacier Select can only do uncompressed CSV files

S3 Event Notifications

- S3:ObjectCreated, S3:ObjectRemoved, S3:ObjectRestore, S3:Replication...
- Object name filtering possible (*.jpg)
- Use case: generate thumbnails of images uploaded to S3
- Can create as many "S3 events" as desired
- S3 event notifications typically deliver events in seconds but can sometimes take a minute or longer
- If two writes are made to a single non-versioned object at the same time, it is possible that only a single event notification will be sent
- If you want to ensure that an event notification is sent for every successful write, you can enable versioning on your bucket.